| |
smartdoc.a7111.com
XML Grundlagen
smartdoc.a7111.com: xml grundlagen DTD DOM XSLT
XPath XSL-FO PDF
Menü
Kontakt:
|
Allgemein
Die eXtensible Markup Language XML ist ein Werkzeug, um strukturierte Dokumente zu erzeugen, die sowohl für Menschen wie auch für Computer gleichermaßen gut lesbar und "verständlich" sind. Genauso wie das bekannte HTML verwendet XML für diesen Zweck Text-Auszeichnungen, Markup genannt. Im Gegensatz zu HTML muss aber bei XML kein umfangreiches Markup-Vokabular beherrscht werden, sondern man "erfindet" ganz einfach ein passendes Markup. Zum Beispiel um einen Brief, ein Buch oder sonstige Publikationen schreiben zu können. So gesehen ist XML einfach zu praktizieren, man ist nur an einige Syntax-Regeln gebunden.
Wie es in der Praxis mit XML tatsächlich aussieht, soll diese Arbeit vermitteln. Aus dem Umfang dieser Arbeit kann die Schlussfolgerung gezogen werden, dass es zum Thema XML doch einiges zu vermitteln gibt. Zum Beispiel zur XML-Sprachfamilie, zu den Metasprachen-Eigenschaften und zu den Präsentationstechniken für XML-Dokumente.
:: Metadaten und Markup
Meta-Daten sind dem Wortsinn nach Daten über Daten und historisch gesehen eine Erweiterung des Begriffes Markup, auf Deutsch Auszeichnung. Eine unbewusst verwendete Art des Markups ist z.B. die Interpunktion im normalen Text: Beistrich, Strich- und Doppelpunkt, Frage- und Rufzeichen sowie im weitesten Sinne auch Klammern, Leerzeichen und Leerzeilen. Dieses "visuelle" Markup unterstützt den Leser beim Erfassen der Information.
::: Korrektursymbole im Redaktionswesen
Ein konkretes Beispiel für Markup ist die im Redaktionswesen noch immer praktizierte Methode, mit Korrektursymbolen Änderungs- und Fehlerhinweise zu notieren (nach Forssman [6]).

::: Steuerzeichen als Markup
Eine andere Art des Markups sind die Steuerzeichen im
ASCII-Code, zum Beispiel CR, LF, FF, SOH, STX, ETX, EOT. Diese und andere "unsichtbare" Steuerzeichen liegen im Bereich $00 - $1F des ASCII-Codes und werden unter anderem für die Datenübertragung verwendet.
SOH TelexNr STX Message... ETX CRC EOT
SOH ... Start of Header
STX ... Start of Text
ETX ... End of Text
EOT ... End of Transmission
CRC ... Checksum
::: HTML, die Hypertext Markup Language
Die genannten Beispiele für allgemeines Markup zeigen die vielfältigen Anwendungsmöglichkeiten, oder besser gesagt, Interpretationsmöglichkeiten, was alles unter Markup zu verstehen ist. Eine spezielle Art von Markup ist jene Notation, die mit HTML und dem Internet populär geworden ist, und die auch für XML verwendet wird.
Innerhalb von Spitzklammern, also zwischen einem Kleiner- und einem Größer-Symbol steht das Markup, dieses Markup wird im konkreten Fall HTML-Tag genannt. Ein Tag-Paar, bestehend aus Start-Tag " <tagname>" und Ende-Tag
" </tagname>", bildet einen zusammengehörigen Komplex, der Dokument-Element genannt wird. Dokument-Elemente wiederum dienen zum Transport von Inhalt, der entweder aus Text oder weiteren Dokument-Elementen gebildet wird. Die Summe der definierten HTML-Tags mit zugehörigen Attributen bildet den Sprachschatz, den diese Markup-Sprache dem Autor zur Verfügung stellt. Das folgende Beispiel zeigt exemplarisch einen typischen (und sehr fehlerhaften!) HTML-Code und das Ergebnis, wie es von einem Browser trotz Fehler richtig dargestellt wird:
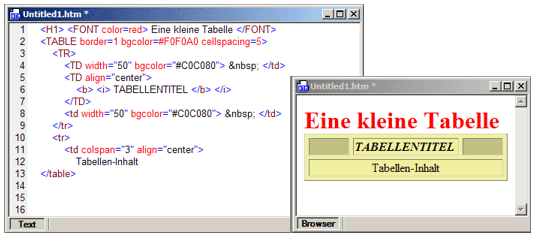
Gängige Browser sind sehr tolerant bei HTML-Dokumenten. Bei einem XML-Dokument würden vergleichbar schlampige Konstrukte nicht akzeptiert werden, da die strikte Einhaltung der sogenannten Wellformedness eine wesentliche Voraussetzung für die Erzeugung eines eindeutigen Dokumenobjektmodells (DOM) ist.
::: Dublin Core Metadaten
Das bekannteste Vokabular für Meta-Daten ist Dublin Core mit einem definierten Satz an Attributen für eine einheitliche Dokumentkategorisierung. Der folgende HTML-Code zeigt die formale Beschreibung einer Verlags-Publikation mit Dublin-Core:
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
<meta name="DC.Format" content="text/html">
<meta name="DC.Language" content="de">
<meta name="DC.Identifier" content="http://oeaw.ac.at/">
<meta name="DC.Source" content="ISBN3-7001-2954-8">
<meta name="DC.Title" content="Civilisation at the Foot of Mt. Sham-po">
<meta name="DC.Subject"
content="Asienforschung: The Royal House of lHa Bug-pa-can">
<meta name="DC.Creator"
content="Tsering GYALBO, Guntram HAZOD, Per K. SORENSEN">
<meta name="DC.Publisher"
content="Verlag der Österreichischen Akademie der Wissenschaften">
<meta name="DC.Rights"
content="Verlag der Österreichischen Akademie der Wissenschaften">
<meta name="DC.Description"
content="The present publication offers to the academic readership
for the first time a translation, transliteration and facsimile
edition of three medieval and rare manuscripts recently traced
in the Central Tibetan monastery of g.Ya'-bzang">
Diese Attribute sind allerdings vorwiegend von administrativem Nutzen und bieten kaum Hilfe für eine substantielle inhaltliche Charakterisierung von Dokumenten.
:: Die Metasprachen SGML und XML
Die Standard Generalized Markup Language SGML wurde 1969 bei IBM von Charles Goldfarb, Ed Mosher und Ray Lorie entwickelt (deren Initialen sich im Begriff GML wiederfinden), und Mitte der 80er-Jahre als Standard anerkannt (ISO-8879).

SGML ist eine Metasprache, die hauptsächlich im Verlagswesen verwendet wurde und eigentlich nur deshalb einem breiteren Anwenderkreis bekannt ist, da sie als Basis für die Entwicklung der Markup-Sprache HTML diente.
Als in den 90er-Jahren erkannt wurde, das HTML nicht mehr für künftige Web-Anforderungen ausreicht, wurde das Stylesheet-Konzept von SGML adaptiert, um anspruchsvollere Formatierungen zu ermöglichen (Cascading Style Sheets CSS). Letztendlich setzte sich aber die Erkenntnis durch, dass für viele zukünftige Web-Anwendungen eine Alternative zu HTML erforderlich war.
Die SGML selbst war aufgrund ihrer Komplexität nicht geeignet, daher wurde sie auf ihre wesentlichen Inhalte reduziert und als eXtensible Markup Language XML neu vorgestellt. XML ist eine Empfehlung (Recommendation) des W3C-Konsortiums und somit ein defacto-Standard. Abgesehen von diesem formalen Status hat sich XML allein aufgrund seiner Eigenschaften als weltweit akzeptierter Standard für Archivierung, Transport und Präsentation von Dokumenten etabliert. Technisch gesehen ist XML sowohl Sprachwerkzeug (Syntax), Metasprache (Werkzeug) und Sprachfamilie (Anwendungen) zugleich.
Als Metasprache dient XML zur Entwicklung neuer Markup-Sprachen und als Sprachfamilie umfasst XML neben den Kernsprachen XSLT, XPath, XSL-FO, XLink, XPointer und XML-Schemas bereits mehrere hundert Anwendungssprachen wie zum Beispiel SOAP, WSDL, XMLDSig, SAML, BPEL, eBXML, GovXML, RuleML, LegalXML usw.
:: Hello World Beispiel
Wieviel Aufwand erfordert es, um mit einer Programmiersprache die Worte "Hello World" am Bildschirm anzuzeigen. In Hochsprachen wie Java und dotNET ist eine Compilation, oft unter Einbindung von spezifischen Funktionsbibliotheken, erforderlich. In HTML geht es relativ einfach, man speichert das folgenden Script in einer HTML-Datei und benutzt einen Browser zur Anzeige:
<html>
<body>
<p> Hello World </p>
</body>
</html>
In XML geht es noch einfacher: <Greetings> Hello World </Greetings>. Anstelle eines von HTML vorgegebenen Vokabulars (body, p) wird ein passendes Vokabular (Greetings) erfunden. Zugleich wird damit auch eine neue Markup-Sprache erfunden, die in diesem Fall allerdings nur ein einziges Sprach-Element besitzt.
::: Ein mehrsprachiges Hello-World Beispiel
Um das Hello-World Beispiel etwas kreativer zu gestalten, bietet sich an, ein mehrsprachiges Gruß-Dokument zu entwerfen:

Dieses Beispiel zeigt, das XML-Dokumente problemlos anzeigbar sind. Voraussetzung für die korrekte Darstellung der kyrillischen Zeichen (strastwuij mir), die mühsam als Unicode-Entities eingetippt wurden, ist natürlich die slawische Zeichensatz-Erweiterung. Aber das ist im Moment nebensächlich, irgendwie überraschend ist eigentlich die Tatsache, dass überhaupt etwas angezeigt wird. Man erkennt, dass ein Browser XML-Dateien lesen und darstellen kann, dass er also einen sogenannten "XML-Parser" besitzt und ein "Default-Stylesheet" für die Darstellung von XML-Dateien anwendet. Bis auf weiteres soll diese editor-ähnliche Darstellungsart reichen (mangels Vorstellung, wie "Grüße an die Welt" repräsentativ aussehen sollen).
::: XML erlaubt Kraut und Rüben, aber keine Fehler
Um zu zeigen, dass tatsächlich eine beliebig neue Sprache erfunden werden kann, wird das Beispiel erweitert: Äpfeln und Birnen werden symbolisch in einen Korb geworfen und Kraut und Rüben "durcheinander gebracht":
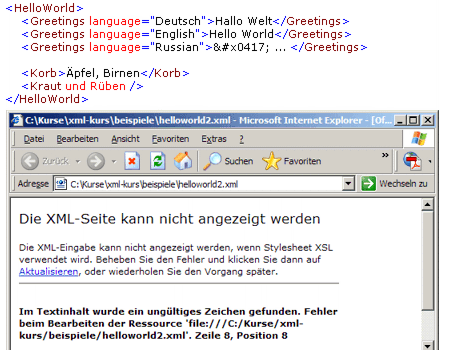
Der Versuch, das erweiterte Dokument anzuzeigen, schlägt fehl. Es wird aber nicht der kodierte Scherz mit Obst und Gemüse bemängelt, sondern formale Fehler:
- Die Worte Äpfel und Rüben enthalten unzulässige Umlaute. XML erwartet Unicode-Zeichen,
ein normaler Editor liefert aber Sonderzeichen aus dem erweiterten ASCII-Zeichensatz
(ISO-8859-1),
- und das Konstrukt
Kraut und Rüben entspricht nicht der XML-Namenskonvention.
Element- und Attributnamen müssen sich, wie in vielen Programmiersprachen, an eine
strikte Konvention halten, die unter anderem Leerzeichen nicht zuläßt.
Das Unicode Problem wird gelöst, indem ein ISO-Zeichensatz für das Dokument angegeben wird. Der richtige Ort für diese Spezifikation ist die formale XML-Deklaration, die in der ersten Zeile eines XML-Dokumentes stehen muß (siehe nachfolgendes Beispiel). Der fehlerhafte Namens-Konstrukt kann ebenfalls formal richtig gestellt werden, wird dadurch aber nicht sinnvoller. Daraus läßt sich erkennen, dass XML-Parser sehr genau auf korrekten Syntax (Wellformedness) achten. Und der kodierte "Scherz" läßt erkennen, dass es wünschenswert ist, das Vokabular einer XML-Sprache genau zu definieren, um nur erwünschte Inhalte zuzulassen. Dies ist Aufgabe einer Document Type Definition (DTD) oder eines XML-Schemas (XSD).
::: Document Type Definition (DTD)
Für die Erzeugung gültiger (valider) XML-Dokumente ist ein Regelwerk erforderlich, dass die inhaltliche Struktur des Dokumentes beschreibt. So ein Regelwerk kann direkt in ein XML-Dokument eingebettet werden, wie das nachfolgende Beispiel zeigt:
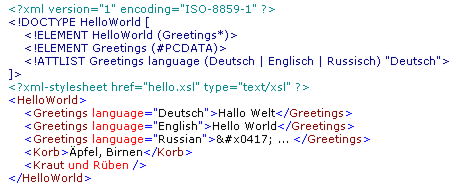
Das eingebettete Regelwerk, eine DTD, kann unmittelbar nach der XML-Deklaration notiert werden. Im gezeigten Beispiel wird ein HelloWorld-Element spezifiziert, das als Inhalt beliebig viele Greetings-Elemente enthalten kann (Kardinalität *). Ein Greetings-Element darf als Inhalt nur reinen Text enthalten (#PCDATA), und es besitzt ein language-Attribut für die Angabe der Gruß-Sprache. Die zulässigen Sprachen sind als Enumeration (Deutsch | Englisch | Russisch) für das Attribut vorgegeben, wobei "Deutsch" der Default-Wert ist bei fehlendem Attribut.
Damit kann das HelloWorld-Dokument von einem validierenden Parser nun auch auf Gültigkeit geprüft werden, und würde wegen des Korb- und Kraut-Elementes als üngültig abgelehnt. Browser sind leider trotzt vorhandenem Regelwerk sehr tolerant und würden keine Fehlermeldung erzeugen, man ist also auf validierende Editoren angewiesen (z.B. XMLSpy), um fehlerfreie Dokumente zu erzeugen.
Was nun noch fehlt, ist eine "anspruchsvolle" Präsentation. Dafür ist ein Stylesheet erforderlich, das im gezeigten Beispiel bereits durch eine sogenannte Processing-Instruction referenziert wird:
<?xml-stylesheet href="hello.xsl" type="text/xsl" ?>
::: XSLT Stylesheet
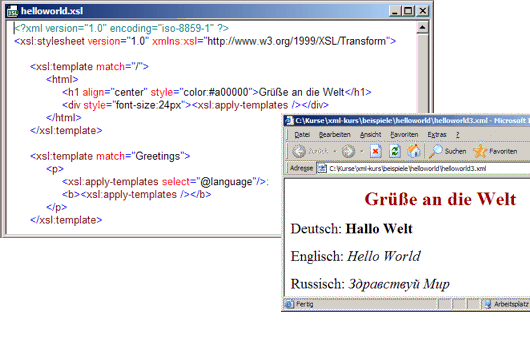
Das nachfolgende Code-Beispiel zeigt den grundlegenden Aufbau eines XSLT-Stylesheets mit den entsprechenden Templates für die Transformation des XML-Dokumentes in das darunter gezeigte HTML-Ergebnis:
XML, DTD und DOM
:: XML als Metasprache und Syntax
XML bedeutet eXtensible Markup Language, auf Deutsch "Erweiterbare Auszeichnungssprache". Diese Begriffserklärung ist in gewissem Sinne irreführend, da sie die Bedeutung von XML nicht im vollen Umfang wiedergibt. Eine Antwort auf
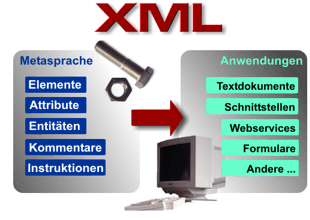
die Frage nach Sinn und Bedeutung von XML ist vielschichtig und hängt vom Niveau und der Intention der Fragestellung ab.
::: Eigenschaften von XML
:::: XML - Allgemeine Aspekte
XML ist eine Meta-Sprache, also eine Sprache zur Beschreibung von Sprachen (in diesem Fall zur Beschreibung von Markup-Sprachen). XML liefert das grundlegende Regelwerk für die Erzeugung neuer Markup-Sprachen, und Markup-Sprachen beschreiben Dokumente und Dokumentinhalte. Sprachen, die mit XML definiert wurden, bezeichnet man als XML-Anwendungen.
Zusammenfassend lässt sich sagen:
- XML ist eine Markup-Sprache ähnlich HTML;
- XML ist reiner Text, somit für Menschen lesbar und angemessen verständlich;
- XML-Text ist durch die verbindliche Markup-Struktur ideal für Maschinen lesbar.
"Wellformedness" und "Validität" sind dabei wichtige Qualitätsmerkmale;
- Der Begriff Text ist dabei im weitesten Sinne zu verstehen. Mit Schriftzeichen
und Zahlen lassen sich nicht nur Text und Daten, sondern auch komplexe Objekte
wie Moleküle und Stadtpläne beschreiben;
:::: XML - Technische Aspekte
- XML ist plattformneutral (reiner Text) und international (Unicode mit über
65.000 Zeichen unterstützt alle Sprachen der Welt);
- XML ist präsentationsneutral und wird erst bei Bedarf in eine Zielsprache
transformiert, zum Beispiel in navigierbares HTML, ausdruckbares PDF,
Sprachsynthesizer-Ausgabe oder SQL-Statements für Datenbanken;
- XML-Dokumente werden üblicherweise durch ein Regelwerk beschrieben
(Schema oder DTD), das zwingende und optionale Strukturen definiert.
Damit eignet sich XML besonders für verbindliche und trotzdem
flexible Datenschnittstellen;
- XML ist objektorientiert (Dokument Objekt Modell DOM). Diese Eigenschaft sieht
man allerdings nicht in der (serialisierten) Textform eines XML-Dokumentes.
::: XML aus Nutzersicht
:::: XML für Autoren
XML ist in besonderem Maße für Autoren und Web-Designer interessant, weil es bei Dokumenten strikt zwischen Inhalt, Struktur und Präsentation unterscheidet. Diese Trennung hat entscheidende Vorteile:
- Durch bedeutungstragendes Markup sind Dokumentstrukturen
"selbsterklärend" und verständlich;
- Ein XML-Dokument ist im Schnitt um 50 % schlanker als ein vergleichbares HTML-
Dokument, da das Markup nur den Inhalt und nicht die Darstellung beschreibt;
- Ein Quelldokument ist für verschieden Präsentationen verwendbar,
zum Beispiel als Buch, als Webseite oder als Sprachausgabe.
:::: XML für Software-Entwickler
Für Software-Entwickler sind die objektorientierten Eigenschaften von XML ein wichtiges Thema. Das Dokument Objekt Model (DOM) als verbindlicher Standard, sowie frei verfügbare
Parser (Xerces), XSL-Prozessoren (Xalan) und entsprechende Klassenbibliotheken
( API) für JavaScript, Java und dotNET sind Stand der Technik.
- Praktisch alle aktuelle Web-Browser (MS-IE, Mozilla) unterstützen den
XML-Standard und das Dokument Objekt Model;
- Ereignisgesteuerte Parser (SAX) erlauben die schrittweise Verarbeitung
großer Dokumente und Datenströme;
- Dokumentorientierte Parser (DOM) erlauben die Erzeugung fertiger und
validierter Objektmodelle eines Dokumentes;
- XSL ist mit seinen Kernfunktionen XSLT, XPath und FO eine mächtige Scriptsprache.
Durch Erweiterungs-Mechanismen wie Java/Javascript-Binding können zusätzliche
Funktionen über externe Sprachen realisiert werden;
- XML-Dokumente brauchen nicht unbedingt ein Anwenderprogramm, sie schaffen sich
als Smarte Dokumente die Anwendung durch XSLT-Transformation selbst.
:::: XML für Software-Architekten
Für Software-Architekten ist XML ein grundlegender Lösungsansatz. Heterogene und objektorientierte Anwendungen profitieren vom Einsatz dieser Technologie.
- XML ist als flexibles und plattform-unabhängiges Konzept gleichermaßen
gut geeignet für Archivierung, Transport, Verarbeitung und Darstellung;
- XML ist das Bindeglied zwischen verschiedenen Datenwelten: "Translating
between Vocabularies" ist in jeder Transaktionsphase möglich;
- Service orientierte Architekturen (SOA) und Webservices basieren auf XML
(SOAP für Datenaustausch,
WSDL zur Servicebeschreibung und Proxy-Generierung,
UDDI als Verzeichnisdienst);
- e-Government-Anwendungen wie elektronischer Akt und digitale Signatur
setzen standardisierte und
kanonisierbare Dokumente voraus;
- Das semantische Web und ontologiebasierende Wissensnetze sind kommenden
Herausforderungen. Die zugehörigen Standards wie
RDF/S,
OWL und Topic Maps
basieren auf XML.
::: Wellformedness und Validität
Unter Wellformedness, auf Deutsch Wohlgeformtheit, versteht man die Einhaltung verbindlicher Syntax-Regeln beim Erstellen von XML-Dokumenten.
- Elemente müssen immer ein Start- und ein Ende-Tag besitzen, also <b> Text </b>,
für leere Elemente ist ein schließender Schrägstrich im Start-Tag zulässig,
zum Beispiel <img src="Bild.gif" />;
- Die Groß-Kleinschreibung ist in XML von Bedeutung (im Gegensatz zu HTML),
<B> Text </b> zum Beispiel ist nicht wellformed;
- Attributwerte müssen mit Anführungszeichen eingeschlossen werden,
also <img src="Bild.gif"> statt <img src=Bild.gif>;
- Elemente müssen korrekt verschachtelt sein, also <b><i> Text </i></b>
statt <b><i> Text </b></i>.
Unter Validität, auf Deutsch Gültigkeit, versteht man die Einhaltung von zusätzlichen Regeln, die durch eine Document Type Definition DTD vorgegeben werden. Validität kann daher nur gegenüber einer DTD geprüft werden, sie ist im Gegensatz zur verpflichtenden Wellformedness eine optionale Eigenschaft von XML-Dokumenten.
:: Document Type Definition DTD
Die DTD (Document Type Definition) als Sprachwerkzeug ist ein Relikt aus SGML-Zeiten und wird immer mehr verdrängt durch XML-Schema. Kenntnisse über Aufbau und Anwendung von DTDs sind aber eine gute Investition für den späteren Umstieg auf Schemas. Die Bedeutung einer DTD für XML-Anwendungen geht wesentlich über den Stellenwert einer Dokumentvorlage hinaus, wie sie zum Beispiel für Word-Dokumente verwendet wird, sowohl in formaler wie auch technischer Hinsicht.
::: Eigenschaften der DTD
::: Formale Aspekte
- Die DTD ist eine formale Grammatik, die Anwendern Informationen über Aufbau
und Variation einer ganzen Klasse von Dokumenten gibt;
- Die DTD ist ein verbindliches Regelwerk (Kontrakt), das in jeder Phase eines
XML-Prozesses Aussagen über die Gültigkeit (Validität) eines Dokumentes erlaubt
(Erstellung-Transaktion-Verarbeitung);
- Für Anwender ist die DTD Voraussetzung, um Dokumente korrekt und vollständig
zu erstellen. Eine gut kommentierte DTD ist zugleich Anwendungs-Dokumentation;
- Für Anwendungsentwickler und Stylesheet-Designer ist die DTD eine systematische
und vollständige Vorgabe, vergleichbar einem Pflichtenheft;
- Jedes gültige XML-Dokument muss eine DTD besitzen, entweder als interner Subset
oder als externe Datei. Dokumente ohne DTD unterliegen nur der Wellformedness
und sind nicht validierbar.
::: Technische Aspekte
- Die DTD erlaubt die Angabe von Default-Werten für Attribute.
Damit werden XML-Dokumente von unnötigem Ballast befreit;
- Die DTD erlaubt die Einschränkung von Werte-Mengen für Attribute,
zum Beispiel "m" oder "w" für das Attribut "Geschlecht";
- Die DTD erlaubt, Entitäten zu spezifizieren, zum Beispiel
Textbausteine oder externe Dokumentteile.
:::: Nachteile der DTD
- Der Syntax unterscheidet sich von XML. Der Autor und die Anwendung
(Parser) müssen eine zusätzliche Sprache beherrschen;
- Die DTD wird nicht durch das Document Object Model (DOM) repräsentiert,
sie kann daher mit XML-Werkzeugen nicht ausgewertet werden (kei Support
für kontextsensitive Editoren, keine dynamische Erzeugung neuer Regeln);
- Die DTD unterstützt keine Namensräume. Verschiedenen XML-Anwendungen
mit gleichen Bezeichnern können daher nicht kombiniert werden;
- Die DTD unterstützt keine Datentypen und keine objektorientierten Konzepte
wie zum Beispiel Vererbung.
:::: Vorteile von Schemas
- Schemas sind XML-Dokumente. Der Syntax unterscheidet sich daher nicht von XML.
Schemas lassen sich als Objekt Modell darstellen und über die DOM-API manipulieren;
- XML-Schemas unterstützen Namensräume (name spaces) und erlauben damit
die Kombination und Segmentierung von Markup-Vokabular;
- XML-Schemas unterstützen einfache und komplexe Typdefinitionen und bieten
Datentypen wie z.B. String, Integer, Boolean, Float, Decimal, Time, Binary, URI;
Weiters stellen Schemas mit Regular Expressions ein mächtiges Werkzeug für die
Modellierung von Dateninhalten zur Verfügung;
- XML-Schemas unterstützen einfache objektorientierte Konzepte,
zum Beispiel Vererbung und Komposition.
::: DTD Deklaration
Eine Document Type Definition wird mit einer "Document Type Declaration" im XML-Dokument deklariert. Dieser Satz ist so ein Ungetüm, daß er auch in der englischsprachigen Literatur immer humorvoll kommentiert wird: "don't confuse them"! Die Abkürzung DTD wird nur für den Begriff Document Type Definition verwendet, und die DTD ist es auch, die uns in weiterer Folge interessiert.
Im einfachsten Fall kann eine DTD direkt im XML-Dokument vorhanden sein. Das Dokument ist damit nicht von einer externen DTD abhängig und kann somit direkt und jederzeit auf Gültigkeit überprüft werden. Gängige Praxis ist das allerdings nicht, da gerade die zentrale Bereitstellung und Pflege den verbindlichen Status einer Dokument-Definitionen ausmacht.
:::: DTD als interner Subset
Innerhalb eines XML-Dokumentes, im sogenannten Prolog, wird eine DTD in folgender Form deklariert und im Detail spezifiziert (am Beispiel eines Brief-Modells):
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE Brief [
<!ELEMENT Brief (Absender, Empfaenger, Inhalt)>
<!ELEMENT Absender (Name, Adresse)>
<!ELEMENT Empfaenger (Name, Adresse)>
<!ELEMENT ...
]>
<Brief> .... </Brief>
Die DTD-Deklaration wird mit Spitzklammer und dem Schlüsselwort !DOCTYPE eingeleitet und gibt (im gezeigten Beispiel) mit dem Namen "Brief" die Klasse der beschriebenen XML-Dokumente an. Die konkrete Dokument-Modellierung erfolgt innerhalb der DTD-Deklaration in einem Bereich, der von eckigen Klammern umgeben ist. Definitionen in einer DTD beginnen immer mit öffnender Spitzklammer und enden mit schließender Spitzklammer (also nicht wellformed, wie sonst in XML üblich). Die DTD-Deklaration wird ebenfalls mit einer schließenden Spitzklammer abgeschlossen. Das nachfolgende XML-Dokument muß zur Klasse der beschriebenen Anwendungen gehören, also als erstes Element ein Brief-Element haben, um gültig zu sein.
:::: Externe DTD
Die Deklaration einer externen DTD, auch "external Subset" genannt, erfolgt durch das Schlüsselwort !SYSTEM und einem Verweis auf die DTD-Datei:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE Brief SYSTEM "brief.dtd">
<Brief> .... </Brief>
Die externe DTD-Datei kann eine XML-Deklaration enthalten, zum Beispiel um einen Zeichensatz (encoding) zu spezifizieren, obwohl eine DTD keine XML-Anwendung ist:
<?xml version="1.0" encoding="UTF-8" ?>
<!ELEMENT Brief (Absender, Empfaenger, Inhalt)>
<!ELEMENT Absender(Name, Adresse)>
<!ELEMENT Name #PCDATA>
<!ELEMENT Empfaenger #PCDATA>
<!ELEMENT Inhalt #PCDATA>
::: Elemente und Inhaltsmodelle
Elemente werden durch das Schlüsselwort !ELEMENT deklariert und besitzen Inhaltsmodelle, die innerhalb von runden Klammern definiert werden. Element-Namen unterliegen einer strikten Namenskonvention, wie in Programmiersprachen üblich. Inhaltsmodelle können entweder fundamentale Typen sein, oder weitere Elemente enthalten.
:::: Fundamentale Inhaltstypen
- #PCDATA
Dieser Inhaltstyp ist der atomare Text, aus dem letztlich jeder Element-Inhalt besteht.
Dieser Typ darf neben Text auch definierte Entities enthalten (zum Beispiel &).
Entities werden beim Parsen des Textes interpretiert. Undefinierte Entities führen zu einer
Fehlermeldung, zum Beispiel die in XML nicht definierten HTML-Entities! Weiters darf dieser
Inhaltstyp neben normalem Text auch zulässiges Markup enthalten (siehe Mixed Content).
- EMPTY
Dieser Inhaltstyp kennzeichnet leere Elemente, also Elemente, die weder Text noch
Unterelemente enthalten.Solche Elemente transportieren Informationen ausschließlich
über Attribute. Ein Beispiel dafür ist das aus HTML bekannte <img>-Element,
das im Normalfall nur ein Attribut mit einem Verweis auf eine Bilddatei enthält.
- ANY
Dieser Inhaltstyp kennzeichnet beliebigen Inhalt. Elemente mit beliebigem Inhalt sind
in der Entwicklungsphase einer DTD hilfreich, aber auch in einer finalen DTD können
sie Sinn machen.
:::: Inhaltsmodelle
Elemente können statt fundamentalen Inhaltstypen auch untergeordnete Elemente enthalten, diese Subelemente wiederum können aus weiteren Elementen bestehen. Damit lassen sich komplex verschachtelte Strukturen bilden. Diese Strukturen werden durch Inhalts-Modelle beschrieben, die zulässigen Unterelemente, ihre Reihenfolge und ihre Anzahl (Kardinalität) spezifizieren.
- strikter Reihenfolge (UND)
Beispiel: <!ELEMENT Brief (Absender, Empfänger, Datum, Inhalt)>
- Alternative Elemente (ODER)
Beispiel: !ELEMENT Medium (Bild | Ton | Video)>
Beispiel: !ELEMENT Person ((Name, Vorname) | (Vorname, Name))>
- Gemischter Inhalt (Mixed Content)
Beispiel: !ELEMENT Beschreibung (#PCDATA | Begriff | Verweis | Bild)*>
Mixed-Content erlaubt die freie Anordnung und beliebige Wiederholung von Text und Elementen.
In der Definition eines Mixed-Content muß #PCDATA immer an erster Stelle stehen, und das
Inhalts-Modell muß mit dem Kardinalitäts-Symbol "*" abgeschlossen werden.
:::: Kardinalität
Durch die Definition der erlaubten Elemente in einem Inhalts-Model wird eine prinzipielle Struktur vorgegeben, die aussagt, ob und in welcher Reihenfolge Elemente zulässig sind. Die inhaltliche Modellierung läßt sich verfeinern durch Angabe von Kardinalitäten: Wie oft darf beziehungsweise muß ein Element vorkommen. Folgende Kardinalitäts-Symbole werden verwendet:
- ? Optional einmal
- * Null bis viele
- + Einmal bis viele
- Elemente ohne Symbol sind exakt einmal vorgesehen
::: Attribute
Attribute ergänzen Elemente und verleihen ihnen Eigenschaften. Zu einem Element sind beliebig viele Attribute deklarierbar, die unterschiedliche Aufgaben erfüllen:
- Attribute geben Elementen Eigenschaften und steuern ihre Verwendung;
- Attribute können Informationen transportieren, entweder ergänzend
zu den Element-Inhalten oder alternativ dazu;
- Attribute können als eindeutige Ankerpunkte in umfangreichen
Dokumenten dienen, die direkt erreichbar sind (ID-Typ);
- Attribute tragen zur Reduktion des Markups bei, da sie kein Ende-Tag
erfordern. Dokumente mit "geschwätzigem" Markup können damit erheblich
kürzer formuliert werden.
:::: Attribut-Deklaration: Required, Implied oder Fixed
Mit der Deklaration eines Attributes wird der Typ definiert und zugleich festgelegt, ob das Attribut verpflichtend oder optional ist, und ob es einen Default-Wert zugewiesen bekommt:
- Verpflichtende Attribute werden mit #REQUIRED deklariert, beim Validieren
eines XML-Dokumentes wird überprüft, ob alle verpflichtenden Attribute existieren;
- Optionale Attribute werden mit #IMPLIED deklariert;
- Attribute können mit einem Default-Wert deklariert werden. Default-Werte werden
von validierenden Parsern automatisch in das erzeugte Dokument-Modell eingefügt,
wenn das Attribut im Quelldokument nicht spezifiziert ist;
- Ein Sonderfall sind Attribute mit unveränderlichen Wert (Konstanten),
sie werden mit #FIXED und einer Wert-Zuweisung deklariert.
:::: CDATA-Attribute transportieren Informationen
Attribute vom Typ CDATA (Character Data) erlauben freien Text. Damit lassen sich sowohl ergänzende Informationen wie auch reine Metadaten transportieren. Durch Zuweisung von Default-Werten bei der Deklaration lassen sich Standard-Texte oder Eigenschaften festlegen, die bei Bedarf im XML-Dokument redefiniert werden können:
<!ELEMENT p (#PCDATA)>
<!ATTLIST p Thema CDATA #IMPLIED>
Beispiel:
<p Thema="Zustimmung">
Für diese Vorgangsweise ist Ihre Zustimmung notwendig,
welche Sie mit der Zahlung dokumentieren können ...
</p>
:::: Attribute vom Typ ID und IDREF etablieren Beziehungen
Attribut-Werte vom Typ ID müssen im Dokument eindeutig sein. Die Eindeutigkeit wird von validierenden Parsern geprüft. Attribut-Werte vom Typ IDREFmüssen im Dokument als IDs exisitieren, da ein Bezug hergestellt werden soll. Auch das wird von validierenden Parsern geprüft. Damit lassen sich überprüfbare Beziehungen zwischen Dokumentteilen herstellen.
:::: Enumerations-Attribute definieren Wertemengen
Mit Enumerationen lassen sich Wertemengen für Attribute definieren, die als verbindliche Auswahlliste gelten:
<!ELEMENT Greeting (#PCDATA)>
<!ATTLIST Greeting
language (Deutsch | Englisch | Russisch) "Deutsch">
::: Entitäten
Entities enthalten vordefinierte oder wiederverwendbare Inhalte. Der Begriff Entity ist für den HTML-Programmierer kein Fremdwort, in HTML werden Entities als Substitute für Sonderzeichen und nationale Zeichen verwendet. Die mehrere 100 bekannten HTML-Entities finden sich übersichtlich dargestellt in jeder HTML-Literatur, zum Beispiel in SelfHTML unter "Benannte Zeichen". XML geht hier einen wesentliche Schritt weiter. In XML sind Entities ein universelles Vehikel für verschiedenste Inhalte, vom einfachen Zeichen-Substitut über wiederverwendbares DTD-Vokabular bis zu kompletten XML-Dokumenten.
:::: Predefined Entities
Predefined Entities sind Ersatz-Zeichen (Synonyme) für reservierte Markup-Symbole. Es ist naheliegend, daß die für Markup verwendeten Zeichen nicht im normalen Text vorkommen dürfen und daher umschrieben werden müssen. Von XML werden folgende Zeichen ausschließlich für das Markup reklamiert und dafür "Predefined Entities" als Ersatz angeboten:
- & für das kaufmännische Und-Zeichen &
- < für das Kleiner-Zeichen <
- > für das Größer-Zeichen >
- ' für das Apostroph-Zeichen '
- " für das Anführungs-Zeichen "
Apostroph und Anführungszeichen dürfen in normalen Element-Text verwendet werden, sie führen nur bei Attribut-Werten zu einem Konflikt. Das Größer-Zeichen und Ampersand wird im Text allgemein toleriert, sollten aber konsequent als Entity notiert werden. Das Kleiner-Zeichen im Text wird vom Parser als Fehler beanstandet und muss daher zwingend als Entity notiert werden.
:::: General Entities
General Entities werden in der DTD definiert und in den assoziierten XML-Dokumenten verwendet. Sie enthalten üblicherweise Textformulierungen, die oft in Dokumenten verwendet werden, oder deren genaue Schreibweise bei allen Dokumenten gefordert ist:
<!ENTITY copyright "© Firma XY, Wien 2001">
Beispiel:
Dieser Text ist urheberrechtlich geschützt, ©right;.
:::: Externe Entities
Entities können auch als externe Entitäten deklariert werden, damit stellt XML ein mächtiges Werkzeug zur Verfügung, mit dem sich sowohl umfangreiche Projekte organisieren wie auch anspruchsvolle Dokumente-Konzepte

realisieren lassen.
Die Deklaration externer Entitäten, zum Beispiel Kapiteln eines Buches, erfolgt mit dem Schlüsselwort "SYSTEM" und der Angabe einer Datei oder URL. Die deklarierten Entitäten müssen jeweils an der gewünschten Stelle im Hauptdokument instanziert werden. Instanzierte XML-Entitäten sind Bestandteil eines "gültigen" Dokumentes, sie müssen daher selbst gültig sein (der DTD entsprechen) und dürfen nur an erlaubten Stellen vorkommen.
:: XML Verarbeitung und DOM-API
Ein wesentliches Merkmal von XML-Dokumenten ist die strikte Trennung von Struktur, Inhalt und Aussehen. Die Struktur der aufeinander folgenden und ineinander verschachtelten Elemente erlaubt den gezielten Zugriff auf alle Inhalte. Die nachfolgende Abbildung verdeutlicht dieses grundlegende XML-Prinzip der strikten Trennung:

::: XML-Aufbau
Ein XML-Dokument besteht im Wesentlichen aus einem Prolog und einem Body (Document-Element), vergleichbar einem HTML-Dokument mit seinem Head- und Body-Teil. Der Prolog enthält alle Deklarationen und gegebenenfalls Anweisungen für die Verarbeitung ( Processing Instructions).
Das Document-Element enthält alle

inhaltlichen Teile eines Dokumentes, es ist zugleich die Wurzel des Element-Baumes.
Die ebenfalls dargestellte Document Root ist kein Formalismus, sondern realer Bestandteil des DOM. Über die Dokumentwurzel sind alle Teile des Dokumentes erreichbar und manipulierbar, also auch die DTD-Deklaration und die Processing Instruction. In der Praxis ist allerdings nur der Zugriff auf das Document-Element (also dem Body-Teil mit dem eigentlichen Dokument-Inhalt) interessant.
::: DOM API
Das Dokument Objekt Modell (DOM) ist eine plattform- und sprachneutrale Definition für die Abbildungen von Dokument-Strukturen. Die zugrunde liegende W3C-Spezifikation dient als Vorgabe für die Implementierung des DOM in verschiedenen Sprachen (Java, C++). Die Implementierung erfolgt als API (Application Programming Interface), also als einheitliche Schnittstelle zu Anwenderprogrammen.
Das Dokument Objekt Modell wird als Baumstruktur abgebildet und unterscheidet sich damit wesentlich von der bekannten Vorstellung von einem Dokument als sequentiell lesbarem Text. Über DOM-APIs ist der direkte Zugang zu jedem Dokument-Element möglich, also das Einfügen, Ändern und Löschen von Dokumentteilen. Das Dokument Objekt Modell repräsentiert den Inhalt eines Dokumentes in logischer Form, also unabhängig von der Dokument-Grammatik (Markup).
Der Nachteil des Dokument Objekt Modells ist die speicherintensive Repräsentation eines Dokumentes (ca. das 10 - 20-fache der original Dateigröße). Das spielt eine Rolle bei großen XML-Dokumenten, wenn es an die Grenzen der Resourcen geht. Eine Alternative ist in diesem Fall SAX (Simple API for XML), eine ereignisgesteuerte API, die jedes Dokument-Element sofort präsentiert, wenn es vollständig geparst ist. Die Organisation eines Dokumentmodelles bleibt in diesem Fall dem Anwender überlassen.
::: DOM-Implementierung in Javascript (MS IE)
Der MS IE unterstützt ab der Version 5.5 mit seiner DOM-Implementierung den Zugriff auf XML-Objekte. Dafür wurde ein eigenes HTML-Tag geschaffen, nämlich das XML-Tag, das verwendet wird, um XML-Dokumente und XSLT-Stylesheets als Javascript-Objekte zu deklarieren. Damit stehen diese als DOM-Objekte zur Verfügung. Die vollständige Implementierung der DOM-API im MS IE ist von Microsoft ausführlich dokumentiert (siehe http://msdn.microsoft.com/en-us/library/ unter Win32 and COM Development - Data Access and Storage MSXML - DOM).
Das Document Object Model bietet die Möglichkeit, auf Dokumentknoten (Nodes) mit selectSingleNode() zuzugreifen. Ein so erzeugtes Node-Objekt stellt unter anderem auch eine transformNode()-Methode zur Verfügung, über die eine Neutransformation des Dokumentknoten (ein Teilbereich des Dokumentes) erzwungen werden kann. Diese Methode erwartet als Argument ein XSLT-Dokumentobjekt, also ein XSLT-Stylesheet. Für Smarte Dokumente wird diese Methode intensiv genutzt, um dynamische Neutransformationen des Inhalts durchzuführen.
XSL Stylesheets

XSL zählt zu den wichtigen Kernsprachen der XML-Sprachfamilie und ist ein Komplex aus mehreren Sprachkomponenten:
- XSLT: die Transformationsprache XSLT ist für die Erzeugung
eines Ergebnisdokumentes zuständig (Layout und Funktionalität)
- XPath: die Navigationssprache XPath unterstützt die Befüllung
des Ergebnisdokumentes mit gezielten Zugriffen auf Quelldokument-Inhalte
- XSL-FO: die Formatting-Objects Sprache dient zur Erzeugung
druckbarer Dokumente (z.B. PDF)
Wenn man allgemein von XSL spricht, meint man üblicherweise die Transformationssprache XSLT (mit ihrer eingebetteten XPath-Funktionalität). Das klingt etwas verwirrend, wenn man die (kurze) Geschichte von XSL nicht kennt, aber zugleich ist dieser Begriffs-Wirrwarr symptomatisch für eine junge Technik, die sich dynamisch entwickelt und an die Bedürfnisse anpasst.
- XSL ist der usprüngliche Entwurf für eine mächtige Präsentations-Sprache
auf Basis von XML (W3C-Proposal vom 21. August 1997);
- XSL ist eine Weiterentwicklung und zugleich Vereinfachung von DSSSL
(Document Style and Semantics Specification Language), einem Sprachstandard
der frühen 90er-Jahre. Die Verwandtschaft von XSL zu DSSSL ist sowohl technisch
wie historisch vergleichbar mit dem Verhältnis XML-SGML;
- Genauso wie DSSSL verwendet XSL Formatting-Objects für die ausdruckbare
Darstellung von Dokumenten. Die Anforderungen und die vielen neuen Wünsche
an diese Kernfunktion von XSL waren aber so komplex, dass sich XSL erst relativ
spät als praxistaugliches Werkzeug etabliert hat;
- Dessen ungeachtet hat XSL einen durchschlagenden Erfolg erzielt, nämlich mit
der inkludierten Transformations-Sprache XSLT. Dieser Erfolg führte dazu, dass XSLT
als eigene Spezifikation verabschiedet wurde und seit 2000 als Werkzeug zu Verfügung steht.
Die eigentliche Geschichte von XSL beginnt auf einer WWW-Konferenz in Chikago im Jahre 1994 mit einem Vortrag von Sperberg, Mc-Queen und Goldstein, die erstmals konkrete Anforderungen an eine neue Stylesheet-Sprache für das Web formulieren (nach Kay [11]). Dieser Vortrag war Anlass für ein vom W3C-veranstaltetes Workshop in Paris im folgenden Jahr. Im Rahmen dieses Workshops präzisierte James Clark, der spätere Koordinator der XSLT-Entwicklung, unter anderem die wichtige Rolle von Transformationen in Zusammenhang mit Stylesheets (Transformationen im Sinne von Struktur-Umwandlungen, also das, was CSS zum Beispiel nicht kann).
:: Die Transformationssprache XSLT
Mit XSLT-Stylesheets lassen sich gängige Ergebnisdokumente erzielen, also HTML und DHTML, aber auch speziell aufbereitete Textdarstellungen für Menschen mit eingeschränkten Fähigkeiten oder SQL-Statements für Datenbank-Anbindung. XSLT-Stylesheets sind Anwendungsprogramme, im Gegensatz zu CSS-Stylesheets, daher lässt sich XSLT auf unterschiedlichen Niveaus einsetzen:
- XSLT als Dokument-Schablone
Im einfachsten Fall wird XSLT nur als Style-Guide für die Erzeugung eines Ergebnis-Dokumentes verwendet (genau wie CSS). Für jedes im Quelldokument zulässige Element existiert ein Template (eine Schablone), das die Erzeugung des Ergebnisses beschreibt. Die grundlegende Struktur des Quelldokumentes spiegelt sich im Ergebnisdokument;
- Regelbasierende Stylesheets
Hier wird durch Angabe von passiven Anwendungsregeln für Templates bestimmt, welche Inhalte überhaupt dargestellt werden. Damit lässt sich in gewissen Grenzen auch eine Neustrukturierung des Ergebnis-Dokumentes erzwingen, da Templates Inhalte gezielt holen oder unterdrücken können;
- Programmatische Stylesheets
Hier wird durch gezielten Aufruf von Templates und durch die Verwendung von Anweisungen (IF, CHOOSE, WHEN) gezielt eine Neustrukturierung im Ergebnisdokumentes erzielt (z.B. Sortierung, Filterung oder Zusammenfassung von Ergebnissen);
- Interaktive Stylesheets
Diese Funktionalität wird von XSLT nicht direkt unterstütz, da nur das Ergebnisdokument (HTML) eine Interaktion mit dem Nutzer zulässt. Über Javascript ist aber ein Zugriff auf das DOM-Objekt des Stylesheets möglich, und damit auch der Anstoß einer neuerlichen Transformation.
:::: Aufbau eines XSLT-Stylesheets
Den prinzipiellen Aufbau eines XSLT-Stylesheets zeigt das nachfolgende Code-Beispiel für eine einfache XML-HTML Transformation:
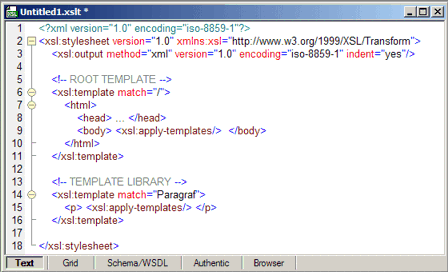
Die erste Zeile des Stylesheets enthält die obligate XML-Deklaration, da Stylesheets XML-Dokumente sind.
Darauf folgt das xsl:stylesheet-Element, das immer das äußerste Element eines Stylesheets ist (das sogenannte Document Element). Dieses Element enthält eine wichtige Information, nämlich die Namensraum-Deklaration für das XSLT-Vokabular (xmlns:xsl='URN'). Alle XSLT-Elemente verwenden diesen Namensraum-Bezeichner vor dem eigentlichen Namen, z.B.
xsl:template statt template, damit unterscheiden sie sich von fremden Vokabular im Stylesheet, wie z.B. HTML im vorangegangenen Code-Beispiel.
::: Templates
Ein Template besteht aus einer Regel mit einem XPath-Ausdruck (match-Attribute). Die Regel bestimmt, wie das Template auf das Quelldokument anzuwenden ist, zum Beispiel match="Kapitel" gilt für alle Kapitel-Elemente. Ein Template besteht weiters aus einen Körper (Body), der Konstrukte (Literal Result Elements) und/oder XSL-Instructions (XSL-Anweisungen) enthalten kann. Die folgende Abbildung zeigt den grundsätzlichen Aufbau eines Templates:

Konstrukte (Literal Result Elements):
Konstrukte sind zum Beispiel Text oder HTML-Markup. Diese Konstrukte werden in das Ergebnis-Dokument kopiert. HTML-Markup innerhalb eines Stylesheets muss "wellformed" sein.
XSL-Instructions (Anweisungen):
XSL-Anweisungen sind zum Beispiel der Aufruf weiterer Templates oder die Anwendung von XSL-Elementen.
Regeln:
Regeln bestehen aus Pfadangaben (XPath-Ausdrücke) und optionalen Bedingungen (Patterns) für das Lokalisieren von Dokument-Inhalten, z.B.:
match="//Buch/Kapitel[@Thema='XSL']/p[1]"
(Navigiere zum ersten Paragraf
(p-Element) eines Kapitels mit dem Thema-Attribut "XSL").
::: XSLT- Funktionen
Funktionen sind eine wichtige Erweiterung des XSLT- beziehungsweise des XPath-Standards. Dass jeweils nur eine Teilmenge der Funktionen in den beiden Standards definiert wurden, spielt beim praktischen Arbeiten keine Rolle, da XSLT ja XPath enthält und somit den gesamten Funktionsumfang zur Verfügung stellt.
- Arithmetische Funktionen: ceiling(), floor(), round()
- String-Funktionen: concat(), contains(), substring()
- Aggregationen: count(), sum()
- Boolesche Funktionen: false(), true(), not()
- Kontext-Funktionen: current(), last(), position()
::: XSLT- Elemente
Der Sprachschatz von XSLT umfasst an die 40 Elemente. Diesbezüglich wird auf die entsprechende Fachliteratur verwiesen (z.B. Kay [11]). Im Folgenden werden einige der XSLT-Elemente aufgezählt, die für das Verständnis der vorliegenden Arbeit von besonderer Bedeutung sind.
xsl:apply-templates:
Diese XSLT-Anweisung führt für eine ausgewählte Menge von Nodes die Transformationen durch Anwendung passender Templates durch. Die Auswahl der betroffenen Nodes erfolgt über das select-Attribut. Wenn das select-Attribut nicht angegeben ist, wird der aktuelle Kontext verwendet.
[1] <xsl:apply-templates />
[2] <xsl:apply-templates select="//Kapitel" />
xsl:for-each:
Diese XSLT-Anweisung erlaubt die Iteration durch eine vorgegebene Menge von Nodes. Damit lassen sich unter anderem gezielt Informationen aus dem Quelldokument filtern, zum Beispiel die Kapitel-Titel für eine Inhaltsübersicht.
<xsl:for-each select="/Kurs/Kapitel">
. . .
</xsl:for-each>
xsl:if:
Diese XSLT-Anweisung entspricht dem aus allen Programmiersprachen bekannten IF-THEN. Das test-Attribut enthält die Bedingung, die erfüllt sein muß, damit der im Body der if-Anweisung enthaltene Programmteil ausgeführt wird. Zu beachten ist, dass ein ELSE-Zweig nicht vorgesehen ist. IF-THEN-ELSE ist aber elegant durch xsl:choose ersetzbar.
<xsl:if test=@autor=Brown >
. . .
</xsl:if>
xsl:value-of:
Dieses XSLT-Anweisung kopiert den Textinhalt einer Node zum Ergebnis-Dokument. Die Auswahl der Node erfolgt über das select-Attribut mit einem XPath-Ausdruck. Enthält die ausgewählte Node keinen Text, so wird nichts erzeugt. Trifft der XPath-Ausdruck auf mehrere Nodes zu, also auf eine Node-Menge, so wird nur der Textinhalt der ersten Node verwendet.
<xsl:value-of select=@autorName>
::: Das XSLT Prozessmodell
Ein XSLT-Prozess (bzw. der XSLT-Prozessor) hat die Aufgabe, ein XML-Quelldokument mit Hilfe eines Stylesheet-Dokumentes in ein Ergebnis-Dokument zu transformieren. Das Ergebnis-Dokument kann ein anderes XML-Dokument sein, ein
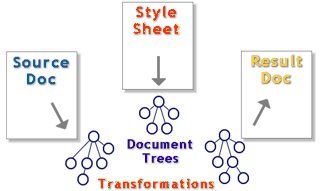
HTML-Dokument, aber auch ein reines Textdokument (ASCII) oder ein formatiertes Textdokument (RTF, PDF).
Wesentliches Kennzeichen des XSL-Prozesses ist, dass alle Dokumente während der Verarbeitung in Baumstruktur vorliegen (Source-Tree, Stylesheet-Tree, Result-Tree) und mit den effizienten Methoden des Dokument Objekt Modells (DOM) manipulierbar sind. Nur beim Laden oder Speichern eines Dokumentes ist das Text-Markup von Bedeutung.
Der Prozess im Detail (nach Kay [11]):
- Der XSL-Prozessor liest (parsed) das XML-Quelldokument und das
XSLT-Stylesheet und bildet beide Dokumente als Dokumentbaum ab;
- Der XSL-Prozessor sucht nach dem Root-Template, das auf die Wurzel eines
Quelldokumentes anwendbar ist. Findet der Prozessor kein Root-Template,
so verwendet er ein vordefiniertes Default-Template;
- Findet der XSL-Prozessor mehrere anwendbare Root-Templates, so tritt eine
Konfliktregelung in Kraft: Entweder wird das Template mit der höchsten Priorität
(priority-Attribut) genommen, oder das zuletzt gefundene;
- Der XSL-Prozessor führt das Root-Template aus, das heißt, alle enthaltenen
XSL-Anweisungen werden durchgeführt:
- zum Beispiel der Aufruf von weiteren Templates,
- oder das Kopieren von Text aus dem Source-Tree zum Result-Tree,
- oder das Kopieren von Text aus dem Template-Body zum Result-Tree.

Kay symbolisiert in seinem Buch "XSLT-Reference" den Transformationsprozess mit einem Rubik-Würfel und kommentiert seine Entscheidung wie folgt:
The mathematics of Rubik's cube relies on group theory, wich is where the notion of closures comes from: every operation transforms one instance of a type into another instance of the same type. Were transforming XML documents rather than cubes, but the principle is the same.
Kay bezieht sich damit sinngemäß auf die DOM-Repräsentation aller beteiligten Dokumente,
und auf die Möglichkeit, komplexe Transformationen in eine Serie einfacher Node-Transformationen zu zerlegen. Die etwas über 40 Trillionen (43*10 18) möglicher Stellungen des Rubik-Würfels lassen sich z.B. durch weniger als 10 Transformationsarten beschreiben, und mit weniger als 20 Transformationschritten lässt sich jeder "verdrehte" Würfel wieder herstellen.
:: Die Navigationssprache XPath
XPath ist ein selbstständiger Sprachstandard des W3C, der nicht nur zur Navigation im XSLT Dokumentbaum (bzw DOM) verwendet wird, sondern auch in Verbindung mit XLink/XPointer zur dokumentübergreifenden Navigation. Die nachfolgende Abbildung zeigt sowohl den formalen wie auch pragmatischen Aufbau eines XPath-Ausdruck:

Axis:
eine optionale Angabe der Dokument-Achse. In der Praxis ist die Angabe der Dokumentachse meist nicht erforderlich, da die meistverwendete Achse, die Kinder-Achse (child-axis) default ist. Die Angabe der ebenfalls oft verwendeten Attribut-Achse wird mit dem Schlüsselzeichen @ abgekürzt.
Node-Test:
Pfad-Angabe zur gesuchten Node. Node-Pfade werden vergleichbar mit Verzeichnis-Angaben notiert, also z.B.
"Buecher/Buch_1/Kapitel_1".
Predicate: optionale Bedingungen oder Filter in eckigen Klammern.
::: Dokument-Achsen
Eine Dokument-Achse ist ein Pfad im Dokumentbaum, der von einer Ursprungs-Node (Origin) ausgeht und alle Nodes berücksichtigt, die in einer bestimmten Beziehung zur Ursprungs-Node stehen. XPath definiert 13 mögliche Achsen, die sich in fünf Kategorien einteilen lassen:
- child-axis, descendant-axis: die Kinder-Achse (child) ist ein Pfad zu allen direkten Kinder-Nodes.
Die Nachfahren-Achse (descendant) ist ein Pfad zu allen Kinder-Nodes und deren Kindern;
- parent-axis, ancestor-axis: die Eltern-Achse (parent) ist ein Pfad zur direkten Eltern-Node.
Die Vorfahren-Achse (ancestor) ist ein Pfad zu allen Vorfahren-Nodes;
- preceding-, following-axis: ein Pfad zu allen vorangehenden (oder nachfolgenden) Nodes mit ihren Kindern;
- preceding-sibling, following-sibling: ein Pfad zu allen vorangehenden (oder nachfolgenden) Nodes,
die eine gleiche Eltern-Node haben;
- self-axis: die Selbst-Achse (self) enthält eine einzige Node (den aktuelle Kontext) und ist niemals leer;
- attribute-axis: Die Attribut Achse enthält alle Attribute der aktuelle Node.
:: Die Seitenbeschreibungssprache XSL-FO
Mit der Seitenbeschreibungssprache FO wurde XSL um eine mächtige Funktionalität erweitert, die die Erzeugung professioneller Druckergebnisse erlaubt. Leider gibt es zu FO kaum praxisorientierte Tutorials, womit man oft auf mühsames Experimentieren angewiesen ist.
Die folgende Abbildung zeigt die grundlegenden Gestaltungsmöglichkeiten für Seitenaufbau und Seitenmanagement in einem FO-Dokument. Ausgehend vom Wurzelelement fo:root sind es die Funktionsgruppen fo:layout-master-set für die Seitenbeschreibung und fo:page-sequence für die Seitenflußkontrolle.
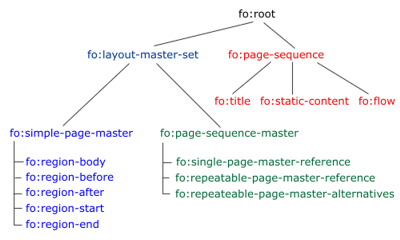
::: Seitendefinition
Das fo:layout-master-set enthält alle für den Dokumentaufbau relevanten Informationen in Form von seitenbeschreibenden fo:simple-page-master und seitensteuernden fo:page-sequence-master. Die Beschreibung der einzelnen Dokumentseiten erfolgt in den jeweiligen fo:simple-page-master. Wenn nur ein einziges Seitenlayout benötigt wird, ist auch nur eine Beschreibung erforderlich. Üblicherweise besitzen Dokumentseiten aber unterschiedliches Layout, zum Beispiel wird sich die Titelseite eines Dokumentes vom Rest der Seiten unterscheiden (keine Kopf- oder Fußzeilen) und gerade Seiten von ungeraden. Das nachfolgende Code-Beispiel zeigt einen fo:simple-page-master für eine ungerade Seite.

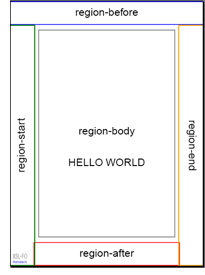
Von besonderer Bedeutung für die professionelle Dokument- und Seitengestaltung sind die optionalen Seitenregionen für statische Inhalte, die aber durchaus dynamischer Natur sein können, zum Beispiel fortlaufende Kapitel-Titel in der Kopfzeile, Seitennummern, Logos an wechselnden Positionen (links-rechts) und Seitenrandmarkierung für die Druckerzeugung.
- fo:region-before (Kopfzeilenregion)
- fo:region-after (Fußzeilenregion)
- fo:region-start (Linke Seitenrandregion)
- fo:region-end (Rechte Seitenrandregion)
::: Die Steuerung des Seitenflusses
Die Steuerung des Seitenflusses erfolgt über fo:page-sequence-master. Es bestehen grundsätzlich zwei verschiedene Möglichkeiten, den Seitenfluß durch Zuweisung eines Layout-Konzeptes mit dem master-reference-Attribut zu steuern:
- entweder durch Zuweisung eines fixen Seitenlayouts, also eines
fo:simple-page-master.
In diesem Fall werden alle Seiten gleich gestaltet;
- oder durch Zuweisung eines variablen Seitenlayouts, das durch einen
fo:page-sequence-master definiert wird. In diesem Fall werden Seiten von
Kriterien abhängig gestaltet, z.B. gerade-ungerade Seiten usw.
Das folgende Code-Beispiel zeigt zwei fo:page-sequence-master für die Erzeugung von einleitenden Seiten (Titelseite, Index) und für die Steuerung des Seitenflusses (gerade und ungerade Seiten).

::: Seitenerzeugung

Mit fo:page-sequence wird im einfachsten Fall das Dokument erzeugt. Hier werden alle Regionen einer Seite befüllt, sowohl mit festegelegtem Inhalt (static-content) wie auch mit dem eigentlichen Dokumentinhalt.
Dokumente mit unterschiedliche Seitenlayouts, zum Beispiel für Titelseite, Indexseiten und Rest des Dokumentes, benötigen mehrere Page-Sequence-Konstrukte, die in richtiger Reihenfolge aufscheinen müssen, jeweils mit einer Referenz auf den erforderlichen Page-Sequence-Master.
::: Block-Elemente
Für die Erzeugung von Seiteninhalten ist fo:block der grundlegende Mechanismus. Praktisch sämtlicher Dokumentinhalt wird innerhalb von Block-Elementen produziert. Das folgende Kode-Beispiel zeigt exemplarisch eine mögliche Konstruktion für einen Kapitel-Titel, eingebettet in ein XSL-Template:

Das gezeigte Code-Beispiel ist nicht mehr trivial. Das Block-Element enthält die Layout-Anweisungen für den Kapiteltitel (Schrift, Absatz), eine mit xsl:number erzeugte hierarchische Kapitelnummer und eine mit generate-id() erzeugte Referenz für das Inhaltsverzeichnis.
::: Erforderliche Werkzeuge
Für die Erstellung von XSL-FO Stylesheets ist grundsätzlich ein normaler Texteditor ausreichend, da XSL-FO wie alle XML-Dialekte auf reinem Text basiert. Aufgrund des erheblichen Sprachumfanges und der durchwegs sehr komplexen Ausdrucke ist aber eine kontextsensitive Eingabe-Unterstützung sehr empfehlenswert, wie sie zum Beispiel der XMLSpy-Editor von Altova anbietet.
Für die Erzeugung der PDF- oder RTF-Zieldokumente sind freie oder kostengünstige XSL-FO Prozessoren verfügbar, z.B. Apache-FOP oder RenderX . Diese setzen allerdings eine Java-Umgebung voraus (z.B. Sun JDK 1.4.2 oder besser).

Der kommerzielle XSL-FO Prozessor von RenderX ist als Trial-Version frei erhältlich. Diese kommerzielle Software unterscheidet sich vom frei erhältlichen Apache-FOP durch eine strikte und vollständige Implementierung des W3C-Standards sowie durch zusätzliche Funktionen, sogenannte "Extensions", die für eine professionelle Dokument-Erstellung sehr hilfreich sind.
Die nebenstehende Abbildung zeigt einen mit XSL-FO erzeugten Kursplaner mit anspruchsvollem Seitenlayout (zum Vergrößern anklicken).
Literaturverweise
- Balzert, H.: Lehrbuch der Software-Technik, Spektrum Akademischer Verlag,
Berlin/Heidelberg, 1996
- Birbeck, M. et al.: Professional XML, 1st Edition, Wrox Press, Birmingham, 2001
- Brown, W. J. et al.: Anti Patterns, Wiley, New York, 1998
- Chen, C., Geroimenko, V.: Visualizing Information using SVG and X3D,
1. Edition, Springer, Berlin/Heidelberg, 2004
- Dueck, G.: Lean Brain Management. Erfolg und Effizienzsteigerung durch Null-Hirn,
Springer, Berlin, 2006
- Forssman, F., Willberg, H. P.: Lesetypographie, Verlag Herrmann Schmidt, Mainz, 1997
- Fuhr, N. (Editor) et al.: Advances in XML Information Retrieval:
Third International Workshop of the Initiative for the Evaluation of
XML Retrieval, INEX 2004, Dagstuhl Castle, 2004, Springer, Berlin/Heidelberg, 2005
- Gomez-Peres, A. et al.: Ontological Engineering, Springer, 2004
- Heyer, G. et al.: Text Mining. Wissensrohstoff Text, Verlag W3L, Bochum, 2006
- Jung, E. et al.: Professional Java XML, Wrox Press, Birmingham, 2001
- Kay, M.: XSLT Programmer's Reference, 2nd Edition, Wrox Press, Birmingham, 2001
- Kuhlen R. et al.: Grundlagen der praktischen Information und Dokumentation,
5. Ausgabe, K. G. Saur, München, 2004
- Krcmar, H.: Informationsmanagement, Springer, Berlin/Heidelberg, 2005
- Larman, C.: UML 2 und Patterns angewendet. Objektorientierte Softwareentwicklung,
mitp-Verlag, Bonn, 2005
- Höhn, R., Rosenkranz, H.: Standards für ontologiebasierende Anwendungen,
in Makolm, J., Wimmer, M.: Wissensmanagement in der öffentlichen Verwaltung,
Österreichische Computer Gesellschaft, Wien, 2005
- Kirk, C., Pitts-Moultis, N.: XML Black Book, Coriolis Technology Press, Scottsdale, 1999
- Markowetz, F.: Klassifikation mit Support Vector Machines. Max Plank Institut
für Molekulare Genetik, 2003
- Mizoguchi, R. (Editor) et al.: The Semantic Web ASWC 2006:
First Asian Semantic Web Conference, Beijing, China, September 3-7, 2006,
Proceedings, Springer, Berlin/ Heidelberg, 2006
- Park, J.: XML Topic Maps. Creating and Using Topic Maps for the Web,
Addison-Wesley, Boston, 2003
- Pöhm, M.: Präsentieren Sie noch oder faszinieren Sie schon?
Der Irrtum Power-Point, mvg-Verlag, Heidelberg, 2006
- Russel, S., Norvig, P.: Künstliche Intelligenz. Ein moderner Ansatz,
Prentice Hall/Deutsche Ausgabe bei Pearson Education, München, 2004
- Schneider, U.: Das Management der Ignoranz. Nichtwissen als Erfolgsfaktor,
Deutscher Universitätsverlag, Wiesbaden, 2006
- Solomon, C.: Anwendungen entwickeln mit Office, Microsoft Press, 1995
- Staab, S., Studer, R.: Handbook on Ontologies, Springer, Berlin/Heidelberg, 2004
- Stein, E.: Taschenbuch Rechnernetze und Internet, Fachbuchverlag Leibzig
im Carl Hanser Verlag, München/Wien, 2001
- W3C, World Wide Web Consortium, w3.org
|
|
|